
热门主题




机器学习隐私风险及防护技术研究
2019-12-12 16:28:2232591人阅读
一、背景
随着AI成为新一代关键技术趋势,围绕着AI的服务也越来越普及。特别是结合了云计算以后,机器学习数据的标注、模型训练及预测等服务纷纷上云,为用户提供了强大的算力和优秀的算法,极大方便了广大开发者与企业用户。但是,随之而来的AI服务隐私泄露风险也日益突显,主要表现在:模型预测服务(白盒or 黑盒)存在泄露训练数据隐私的风险;模型本身在预测服务过程中存在泄露的风险。这些风险不仅会危及到用户敏感数据的安全,还会为AI云服务商带来巨大的经济损失。本文首先总结机器学习中几种典型的隐私泄露风险及其实施手段,随后介绍了我们在防护技术上的一些现行工作。
二、典型威胁
我们主要针对现在流行的MLaaS(Machine-Learning as-a Service)服务模型,介绍几种典型的隐私泄露威胁。一个MLaaS的工作流示意图如下,主要包括了两个阶段: 1、使用数据数据集训练得到模型;2、使用模型提供预测服务。在这两个阶段中,面临的典型攻击包括: model extraction attack(模型提取攻击)、model inversion attack(模型逆向攻击)和membership inference attack(成员推断攻击)。

1、Model Extraction Attack(模型提取攻击)
模型提取攻击主要指攻击者通过有限次访问预测服务的API接口,从预测值反向推测模型的具体参数或结构,或者结合样本和预测值训练出一个替代模型的过程[1]。以线性回归/逻辑回归模型为例,假设模型的参数个数为n,如果攻击者可以用m(其中m>n)个样本进行预测得到预测值,然后可以构建由m个方程组成的线性方程组,通过求解方程,可以获得n个参数的具体值。类似的攻击也可能发生在决策树模型中,例如,攻击者在使用模型预测服务时,可以通过改变样本中某个特征的值来推测决策树的形态,从而重构一个与模型接近的决策树。Tramèr F等人[1]已经在Amazon,BigML的模型预测服务中进行了攻击,取得了很好的效果。
2、Model Inversion Attack(模型逆向攻击)
模型逆向攻击主要指攻击者从模型预测结果中提取和训练数据有关的信息[2],比如,训练数据的一些敏感特征。例如,在一个人脸识别的神经网络模型,提供了人脸识别分类的API,对每个人脸的图片,可以输出预测的人名和对应的置信度。攻击者可以随机构建一个图片,以训练数据中某个人名(如Alice)的预测置信度作为目标,采用梯度下降等方法反复根据API预测结果对图片进行修正,从而获得具有较高Alice预测置信度的图片。这个过程间接获取了训练集中关于Alice的隐私图片信息。特别的,在结合了生成对抗网络后,这种攻击手段尤为见效。
3、Membership Inference Attack(成员推断攻击)
成员推断攻击是指攻击者通过访问模型预测API,从预测结果中得知某个特征数据是否包含在模型的训练集中[3]。这类攻击的威胁在于,如果在某个医疗相关的模型中,知道某人的医疗记录参与某个疾病模型的训练,则可能推断出此人患有这种疾病。一个攻击示例过程如下,攻击者可以根据输入从预测API得到分类置信度,由此获得高置信度的数据集S(或者是符合预测模型分布的数据集)。随后,攻击者利用S可以训练出一系列shadow models,并使用这些shadow models观测某一数据是否存在S中所引起的预测分类置信度的变化,进而可以训练出一个attack model。最后,对于某个需要推断的成员数据,攻击者用模型预测API得到分类置信度作为attack model的输入,最终可获得这个成员是否在训练数据集中的结果。在这种攻击方式中,攻击者仅需要得到预测分类的置信度,不需要知道模型结构、训练方法、模型参数、训练集数据分布等信息。特别对于过拟合的模型,这种攻击更有效[3]。
三、防御手段
上文所述的攻击,不仅发生在机器学习预测服务场景中,也会发生在联邦学习等会出现模型预测输出的场景中。因此,采取有效的防范措施来降低模型隐私攻击造成的风险十分有必要。总体来说,防御的手段可以分为几类:
1、访问审计与控制
现有的模型隐私攻击都依赖于从预测服务API获取预测输出信息。可预见的是,用于攻击目的对预测API的访问分布和正常使用模型预测服务的访问分布是有区别的。如果能识别出这种区别,那么可以针对性对攻击访问请求进行阻断,从而防止攻击的发生[4]。另外,通过对模型预测API的访问次数和频率进行限制,可以从根本上增加攻击者获取预测信息的成本,从而提高攻击的难度;
2、置信度模糊处理
在模型提取攻击、模型逆向攻击等手段中,通常需要依赖模型输出对于每个预测分类的置信度信息。如果对置信度信息进行合理的模糊化,如取整处理(rounding),既可以保证预测分类信息的准确性,又降低了暴露的置信度的精度,使得攻击者在试探的过程中难以扑捉到置信度的详细变化,从而提高了攻击收敛的难度[1];
3、差分隐私保护
差分隐私技术可以在模型训练过程中或者在最终的模型参数中,为敏感信息添加随机噪声,使得攻击者无法探测到原始训练数据的变化对于模型输出的影响,从而增加了模型提取、训练集探测等攻击的难度[5];
4、集成方法
训练集隐私信息进行探查的攻击方式(如成员推断攻击),所依赖的原理是模型本身的泛化度不够,存在一定过拟合现象。所以,对于具有某些特征的输入,模型的预测输出可以很容易与其它输入的预测结果区别开来。因此类似于PATE(Private Aggregation of Teacher Ensembles)的方法中,采用了将训练数据集进行切分,单独训练出一批model,随后在预测的时候使用集成学习的方法(ensemble)对这些模型的输出结果进行投票,并利用差分隐私对投票结果进行加噪扰动,使得最终的预测结果屏蔽了模型过拟合现象带来的影响[6]。
四、 现行工作
在机器学习隐私泄露风险日益凸显的形势下,有必要了解典型的机器学习隐私泄露攻击方式并掌握切实有效的防护方法。因此,我们建立了一套机器学习模型隐私风险评估体系,并提供相应的保护技术手段。机器学习模型的隐私风险评估体系包括了1)隐私保护能力测试集(Benchmark),由针对模型和训练数据提取的测试工具构成;以及2)基于测试工具集的模型隐私风险量化评估模型。在保护技术中,我们提供一系列以差分隐私为主要技术手段的模型训练和保护算法,总体示意图如下:
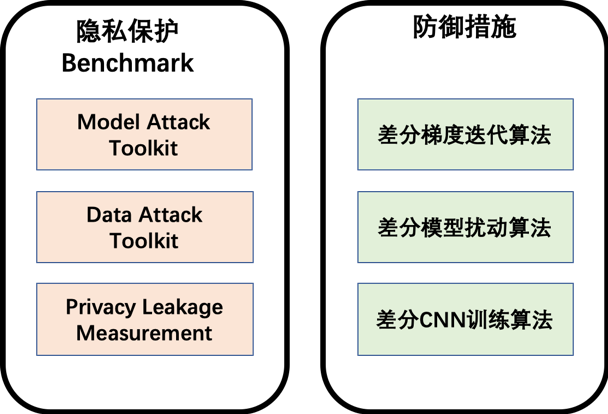
1、隐私保护能力测试集
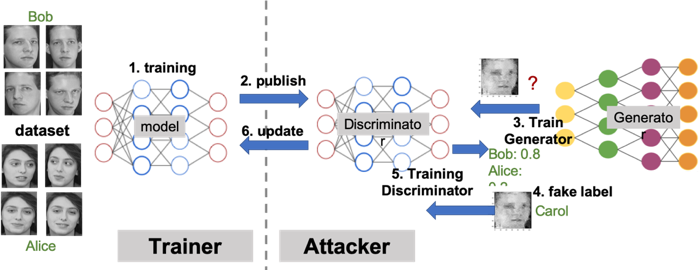
目前,在隐私保护能力测试集中,我们提供了成员推断攻击和基于GAN(生成对抗网络Generative Adversarial Network)的模型逆向攻击工具的实现,并在公开数据集上进行了验证。例如,当基于GAN的模型逆向攻击工具被用于在联邦学习过程中,对对方模型进行攻击的一个例子如下:
模型训练者先使用自己的数据集训练更新联邦学习的模型,攻击者作为一个正常参与联邦学习参与者,会下载模型用作判别网络,然后构造生成网络,并使用判别网络不断迭代生成网络,产生攻击样本,然后打上假标签用来更新联邦学习模型。不断重复以上过程,攻击者构造出来的生成网络就可以产生参与者的训练数据,比如Bob的头像信息。
攻击完成后的效果如下(左图为原始参与模型训练的图片,右图为攻击者恢复的图片)。

2、隐私风险量化评估指标
如何度量机器学习模型的隐私泄露风险,是风险评估体系中的重要问题。文献[7]和[8]提出借鉴密码学中常用的思维实验中的敌手优势(Adversary Advantage)概念,并将其与具体的攻击工具相结合,从而形成一套评估模型隐私泄露风险的量化指标,称为隐私泄露指数(Privacy Leakage)。在我们的风险评估模型中,隐私泄露指数是重要的量化指标之一。
以下简要描述成员推断攻击下模型的隐私泄露指数定义。首先将成员推断攻击形式化定义为实验ExpM(Å, A, n, D),其中Å代表敌手算法,A为机器学习算法,n为正整数,D为数据集上的分布。实验的过程如下:
1. 从Dn中采样得到S,并令AS=A(S);
2. 从{0, 1}中随机均匀选择得到b;
3. 如果b=0, 从S中抽取样本z,否则从D中抽取样本z;
4. 如果Å(z, AS, n, D)=b,则令ExpM(Å, A, n, D)=1,否则为0(Å的输出只能为0或者1)。
在此实验定义基础之上,进一步定义一个成员推断攻击敌手(算法Å)的优势(Membership Advantage)为:
AdvM(Å, A, n, D) = 2Pr[ExpM(Å, A, n, D) = 1] - 1
此定义描述了敌手算法Å与随机猜测相比之下,所具有的攻击优势。可见敌手优势越大,进行成员推断攻击的成功率越高。在敌手算法不变的情况下,优势越大,说明模型抵御攻击能力越弱,发生隐私泄露风险越高。因此,在成员推断攻击方法确定时,模型的隐私泄露指数可以定义为相应的推断攻击优势。同样的,模型逆向攻击下的模型隐私泄露指数也可以采用模型逆向敌手优势进行定义,细节可参见[7][8]。
特别地, 上述定义的优势可以转换为true positive rate(TPR)与false positive rate(FPR)的差值。例如,有100个成员记录,100个非成员记录,进行成员推断攻击时,如果攻击者可以正确地识别到100个真实的成员记录,而错误地将30个非成员记录识别成member,则隐私泄漏值为1-0.3=0.7。
建立起隐私风险的量化评估指标后,我们可以进一步评估防御手段的优劣。通常隐私保护的代价是在一定程度上牺牲模型的可用性(比如分类的准确性)。因此,我们在判断一个防御方法好坏的时候,需要同时考虑可用性和隐私泄漏。我们可以结合隐私泄露指数以及模型准确度损失来衡量防御方法的效果,其中准确度损失定义为:
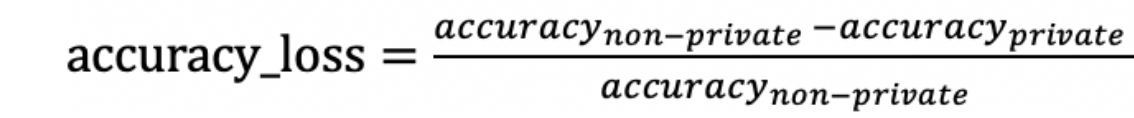
防御手段的隐私泄露指数以及模型准确度损失越小,防御手段表现越好,表明该方法在对可用性影响较小的情况下保证了较少的隐私泄漏。
3、模型隐私保护工具
我们主要依赖差分隐私技术,提供了针对模型逆向、成员推断以及模型窃取的保护算法。例如,为了解决发布模型对外提供服务泄漏训练数据集隐私信息的问题(模型逆向攻击和成员推断攻击),我们在百度飞桨框架上(PaddlePaddle),实现了支持隐私保护的梯度优化,包括DP-SGD、DP-Adam、DP-Momentum、DP-AdaGrad等。其中DP-SGD算法已经开源(https://github.com/PaddlePaddle/Paddle/tree/develop/paddle/fluid/operators/optimizers)。这类算法通过裁剪梯度并添加高斯噪声的方法,有效地保护了训练数据集,且训练出来的模型准确度与原本算法几乎一致。
另外,我们也尝试了在模型预测阶段添加噪声来抵御模型窃取攻击的方法,以及在卷积神经网络中浅层的卷积层上添加噪声的方法,均取得了良好的效果。
五、未来工作
机器学习的隐私泄露及防御是一个动态的攻防过程。随着技术的不断发展,特别是联邦学习、MLaaS模式的流行,针对模型的隐私窃取手段会越来越多样化,防御所面临的挑战也越来越大。特别是在隐私保护和数据可用性这一本质矛盾的前提下,如何提供符合场景需求的保护方法,最小化机器学习中的用户隐私的泄露风险,将是个长期的挑战。
因此,从技术手段方面,有必要持续关注机器学习隐私窃取攻击手段的演化,并验证其实施的难度和效果。同时持续推进防御手段研究工作,特别是针对深度学习模型(隐私性和可用性的平衡)以及树模型(如GBDT等,由于其可解释性更容易发生隐私泄露)的隐私保护训练算法。
从安全管理方面,希望能够实现风险的提前感知与收敛。因此,可以基于成熟的技术手段及量化风险评估体系,建设覆盖:模型风险初步评估→ 模型测试→ 风险量化评估 → 反馈评估报告 → 提供参考改进技术手段 → 测试并评估改进结果等环节在内的,针对模型隐私泄露风险的完整评估服务闭环。
参考文献:
[1] Tramèr F, Zhang F, Juels A, et al. Stealing machine learning models via prediction apis[C]//25th {USENIX} Security Symposium ({USENIX} Security 16). 2016: 601-618.
[2] Fredrikson M, Jha S, Ristenpart T. Model inversion attacks that exploit confidence information and basic countermeasures[C]//Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. ACM, 2015: 1322-1333.
[3] Shokri R, Stronati M, Song C, et al. Membership inference attacks against machine learning models[C]//2017 IEEE Symposium on Security and Privacy (SP). IEEE, 2017: 3-18.
[4] Kesarwani M, Mukhoty B, Arya V, et al. Model extraction warning in mlaas paradigm[C]//Proceedings of the 34th Annual Computer Security Applications Conference. ACM, 2018: 371-380.
[5] Abadi M, Chu A, Goodfellow I, et al. Deep learning with differential privacy[C]//Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2016: 308-318.
[6] Papernot N, Abadi M, Erlingsson U, et al. Semi-supervised knowledge transfer for deep learning from private training data[C]. arXiv preprint arXiv:1610.05755, 2016.
[7] Jayaraman B, Evans D. Evaluating Differentially Private Machine Learning in Practice[C]//28th USENIX Security Symposium (USENIX Security 19). Santa Clara, CA: USENIX Association. 2019.
[8] S. Yeom, I. Giacomelli, M. Fredrikson and S. Jha. Privacy Risk in Machine Learning: Analyzing the Connection to Overfitting. 2018 IEEE 31st Computer Security Foundations Symposium (CSF), Oxford, 2018, pp. 268-282.
本文由百度安全先进隐私保护技术团队原创,转载请标明出处及原文链接