
热门主题




百度世界大会公开课 | 人工智能的安全威胁:深度学习中的攻防对抗分析
2020-09-16 12:40:4223598人阅读
在数据丰沛的时代,计算机可以通过自我学习获得算法,把数据转化为知识。深度学习是当前机器学习技术中最为炙手可热的一种。深度学习的实质,就是通过构建具有很多隐层的机器学习模型和海量的训练数据,来学习更有用的特征,从而最终提升分类或预测的准确性。
通俗地讲,图片识别就是通过抓取数据的核心图像特征,从而辨识数据的类型并将其归类。比如,如果想判断图片中是一辆摩托车,那就只要抓取“有两个轮子”“有踏板”等特征便可以完成判断。过去由于图片识别的精准度不高,这种判断很难由机器完成,深度学习的出现便让这一问题迎刃而解。
近年来,随着深度学习技术的发展和各种模型的不断涌现,基于深度学习的计算机安全应用研究也成为了计算机安全领域里的一个热门研究方向。深度学习模型容易受到对抗样本的恶意攻击,这在业内已不是新鲜事。对图像数据添加人类难以通过感官辨识到的细微扰动,便可“欺骗”模型,指鹿为马,甚至无中生有。为实施此类攻击,攻击者往往需要提取模型结构、参数,继而利用特定算法针对性地生成“对抗样本”,诱导模型做出错误的,甚至攻击者预设的判别结果。
据介绍,在真实的物理世界中,依据这一原理,百度安全研究员已经进行了不少骚气的实验操作:
Blackhat欧洲大会上,我们重现了大卫科波菲尔让自由女神像消失的魔法。通过控制一辆Lexus背后的显示器上显示的画面,我们可以让著名的目标检测模型YOLOv3完全识别不出Lexus。同样的,我们也可以让一个‘停止’的交通标示在目标检测模型里被误认为是一个限速的标示。可以想象由此产生的识别错误会给安全攸关的驾驶场景带来麻烦。

当然,上面所提到的一些实验案例,是基于对深度学习模型高度认知的前提下,我们把这种提前知道模型内部构造,可以利用特定算法来生成“对抗样本”的攻击,叫做“白盒攻击”。然而,对于诸如语音识别、无人驾驶等对安全性有极高要求的行业中,攻击者并不一定能获取这些深度学习模型的模型框架和训练数据等详细内部构造信息,对模型的认知程度不高,这种类型的攻击就被称为“黑盒攻击”。显然,相较而言,“黑盒攻击”的难度更大,所以 AI 开发者们最好保护好自家的 AI 模型,避免让攻击者知道其内部构造。
然而,只是保护好自己的模型构造就足够了吗?百度安全研究员最近研究发现 —— 黑盒模型也未必更加安全。

我们发现许多实际分类应用的模型往往都是基于一些预训练模型。而这些预训练模型都是公开的。当攻击者把攻击目标从黑盒模型转移到它的父模型后(当中我们用了一个指纹攻击的技术完成对父模型的匹配),攻击难度就相对的降低。而成功攻击父模型后生成的对抗样本,同样可以利用攻击迁移性的特点有效地对黑盒模型实施打击。
公开课的最后,百度安全研究员介绍了百度安全针对对抗样本的解决思路,以及通过对抗训练强化模型来提高深度学习模型鲁棒性的途径。百度安全针对人工智能算法安全性的研究,包括深度学习模型鲁棒性测试、形式化验证、机器识别恶意样本实时监测、黑白盒攻防等领域。
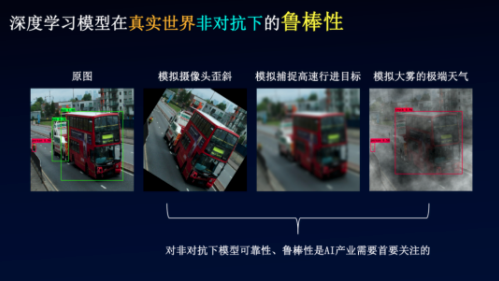
在深度学习对抗上,我们在Github开源了AdvBox,Perceptron Benchmark工具。其中Perceptron Benchmark为深度学习模型的鲁棒性评估提供了标准的评测方法,同时也为模型鲁棒性的提升提供了有效的标准数据集。AdvBox集成了业界深度学习对抗的算法。此项技术已在Github完成开源,并登上了Black Hat、DEFCON等国际工业界会议,受到全球安全行业的关注和认可。同时,Advbox也已应用于百度深度学习开源平台PaddlePaddle及当下主流深度学习平台,可高效地使用最新的生成方法构造对抗样本数据集用于对抗样本的特征统计、攻击全新的AI应用,加固业务AI模型,为模型安全性研究和应用提供重要的支持。
我们希望能够通过百度安全的技术与服务,让更多人享受到科技带来的便利,让更多企业获得更加安全的 AI 解决方案。