
热门主题




企业级自动化代码安全扫描实战
2019-02-12 14:36:4514337人阅读
一、概述
源代码安全检测是安全开发流程(SDL)中举足轻重的一部分,一般通过人工审计或者自动化工具来进行检测。在大型企业中,业务线情况较为复杂,项目开发往往使用不同的编程语言、开发框架,编码风格也大不相同。此外,存量的代码有上亿行、每天又会有大量的新增代码与项目,这些因素导致在大型企业安全实践中是无法通过人工审计代码的方式来进行检测的。因此,在人力紧张以及工作量庞大的情况下,最优的选择是依赖自动化检测工具了。
本篇文章中,主要介绍我们自主研发的静态代码安全检测平台的整体技术原理、研发部署方案与架构、总体检出效果,以及一些具体生产环境的检出场景。
二、自动化代码漏洞挖掘技术
2.1 基于污点传播分析的自动化挖掘技术
2.1.1 检测模型
自动化代码安全检测是一种自动化挖掘、发现源代码漏洞的安全检测。我们在人工形式下的代码审计中,通常关注以下三点:
输入源
即用户输入可进入代码逻辑的入口,如PHP语言中的GPC,JAVA语言中的HttpServletRequest等等。此外,在对框架开发的工程进行代码审计的时候,我们还会关注框架自身封装的一些入口方式,比如SpingMVC中的@RequestParam注解。
净化操作
净化操作包括两个部分:系统自带的净化操作函数以及用户自定义的净化操作函数。
这些净化操作函数通常可以针对某种漏洞类型将传入的参数进行一定程度的字符串变化,从而消除某种漏洞的威胁。比如htmlspecialchars函数,被广泛认为是用于消除XSS漏洞影响的,虽然在某些场景j下一样可以被绕过。
危险函数
危险函数是触发漏洞的位置,一般按照漏洞类型进行分类别讨论。比如SQL注入漏洞的PHP危险函数为mysql_query,调用该方法执行查询,如果一旦危险参数可控,则会造成SQL注入漏洞。
现在我们来将这三个要素串联起来,实际上每次代码审计判断一个可疑点是否有漏洞(注意这里是指的常规的Web安全漏洞,不包含逻辑漏洞),都是运用的以下模型:

本章节就是要讨论如何将上述过程进行自动化,且能够嵌入到互联网公司的SDL流程中。
目前市面上有基于正则表达式和基于语义分析的两种检测方式,基于正则表达式的传统代码安全扫描方案的缺陷在于其无法很好的“理解”代码的语义,而是仅仅把代码文件当作纯字符串处理。目前较为成功的静态扫描商用产品都运用了语义分析、语法分析等程序分析技术,如开源的Rips中,使用的是PHP内置的Tokenizer系列API来获取token流。
${RIPS_HOME}/lib/scanner.php文件:
// tokenizing
$tokenizer = newTokenizer($this->file_pointer);
$this->tokens = $tokenizer->tokenize(implode('',$this->lines_pointer));
unset($tokenizer);
在token流的基础上进行分析,可以通过每个节点的解析器代号对代码进行一定程度的理解,如T_ABSTRACT表示抽象类、T_AND_EQUAL代表赋值运算符。
除了在token流的基础上执行代码分析,市面上越来越多的代码漏洞扫描器选择了从抽象语法树层面入手执行代码分析,相比冗长的token流,语法树层面的分析显得层次分明、容易理解,这对于平台开发人员来说是个好消息。
通过更加高级的语义、语法分析,我们可以从待分析的代码中获取更多的信息,通过这些信息,就能够大大提高漏洞检测的准确度,这也是为什么目前绝大多数商用软件都选择在语义、语法分析的基础上执行代码安全检测。
2.1.2 系统层次
接下来,我们将会以PHP语言为例,介绍一个自动化白盒扫描系统中所需要的各个方面,以及给出从静态分析层面构建一个自动化代码安全检测系统的思路。
我们先有一个整体的认识,一个基于程序静态分析的自动化审计系统大致应该有以下几个部分:
(1)静态分析层
静态分析层负责对代码文件进行“理解”,完成语义、语法层面的分析,比如生成抽象语法树、生成程序的控制流图等基础的分析结构。同时,针对PHP语言的一些变量类型进行分类抽象,用于后续的数据流分析中。
(2)数据流分析层
数据流分析主要负责收集代码中的变量传递流向,同时收集变量的净化情况。数据流分析是污点传播分析的基础,其收集的信息越全面越准确,后续的污点传播分析才会准确。
(3)污点分析层
污点传播分析是依照数据流分析过程获取的一系列程序信息来进行漏洞判定的模块。
(4)其他分析层
其他分析包含针对PHP多个代码文件的联合检测、结合程序的上下文信息进行更加细化的漏洞判定分析、过程内和过程间分析等等。
2.1.2.1语义语法分析
抽象语法树(Abstract syntaxtree, AST)是将源代码按照一定的语法结构,并且将一些冗余的细节抽象为树状结构进行表示。市面上有很多语义语法分析工具,如ANTLR,Yacc,Lex,PHP-Parser等等。
这里着重介绍一下PHP-Parser(https://github.com/nikic/PHP-Parser),作为PHP语言的语法分析工具,其本身就是使用PHP语言进行实现的,且支持节点遍历等功能。使用composer可以很方便地安装PHP-Parser:
// 安装composer:
curl -s http://getcomposer.org/installer | php
// 安装PHP-Parser:
php composer.phar require nikic/php-parser
具体使用可以参考官方文档。
2.1.2.2 控制流分析
仅仅在抽象语法树的基础上进行分析是不够的,因为抽象语法树无法很好的获取程序中流程控制语句的信息。比如分析以下示例代码时,如果不考虑程序中的分支判断,则很容易发生误判:
<?php
$username = $_GET['username'] ;
$data = $_GET['data'] ;
if($username == 'alice'){
$data= "[data]" . $data ;
}else{
$data= intval($data) ;
}
eval($data) ;
当分析到程序调用了eval函数,则向上回溯$data变量,结果发现在else分支中调用了intval,如果不考虑控制流程,即不考虑其他的代码分支,这时审计程序就会认为该代码片段不存在问题直接返回,显然这是错误。因为在if分支中,出现了另外的赋值,如果只进入这个if分支,那么就会触发代码注入漏洞。
因此我们需要在抽象语法树的基础上构建控制流程图,将PHP中的分支跳转进行整理,以基本块的形式编排抽象语法树的节点。比如针对上文的代码片段生成控制流图:
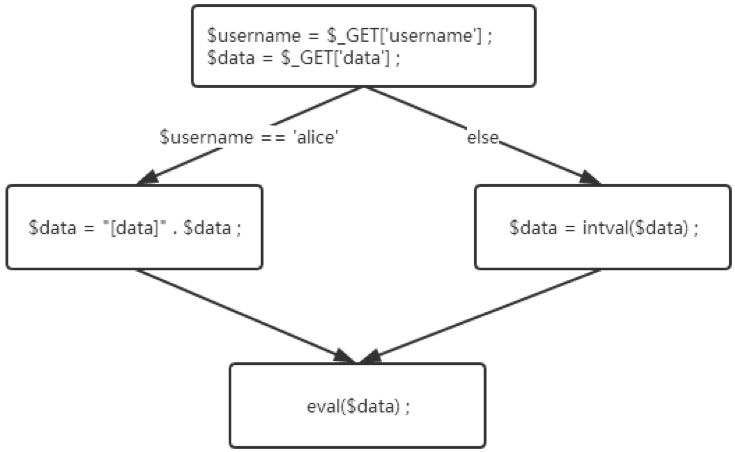
在程序分析的时候,必须要对每个分支进行独立的分析。
生成新基本块的依据是一些控制流程语句,这些语法结构都是固定,大致有以下几种:
条件分支
If语句、Switch语句、Try catch块、三目运算符、Or语句
循环结构
For语句、Foreach语句、While语句、Do…While语句
终止结构
Break、Continue、Throw
返回结构
Return
生成控制流图的方法是当遇到条件分支和循环结构时,需要生成一个新的基本块,将这些代码块中的语法树节点插入进去;当遇到终止结构时,停止当前基本块的生成;当遇到返回语句时,停止图的构建。
2.1.2.3 抽象内置函数
在任何代码中,都会有PHP内置函数的调用,如果不对这些内置函数进行处理,或者说自动化分析不“理解”这些函数的含义和效果,可能会造成大量的误报,比如分析下面的代码片段:
<?php
$comm = “touch ” ;
$name = $_GET[‘name’] ;
$hash = md5 ($name) ;
system($comm . $hash) ;
由于PHP内置函数众多,每个函数都人工进行处理是不现实的,最好的方式是对这些内置函数进行分类。按照功能和对程序分析的影响,大致可分为:
(1)返回常量值
比如strlen()或者md5(),一旦参数进入这些内置函数将会返回常量类型的结
果,比如返回纯数字、布尔值、纯字符串,这种处理需要考虑为针对参数的一种净化方法。
(2)返回参数的一部分
某些内置函数如trim() 或者 array_keys() 会将参数的一部分或者全部进行返回。针对返回值,该分类可以分为返回array、返回array的单个元素、返回string类型。
(3)净化操作
针对某种漏洞类型进行参数净化操作的内置函数,比较典型的有addslashes,
htmlspecialchars等函数。
(4)字符串切割变换
比如内置函数substr()或者chunk_split(),这些内置函数会返回传入参数的一个子串。由于这种操作会破坏参数原有的结构,如果不追求绝对精确分析的话,实际上完全可以将这类函数的调用视为某种程度的净化处理。
(5)编码和解码函数
编码函数
如urlencode()或者base64_encode()等执行某种编码操作的内置函数。
解码函数
如urldecode()或者base64_decode()等执行某种解码操作的内置函数。注意,如果在分析中遇到了解码函数,通常认为该函数调用前参数所受到的一切净化都是无效的,如果直接进入危险函数就会触发漏洞。
(6)回调函数
一些内置函数会执行参数指定的其他函数,比如array_walk(),array_map(), set_error_handler()。如果标识其他函数名的参数可以直接获取到,那么将该调用信息进行进一步分析,比如以下代码片段:
$NAMES = array(
‘1’=> $_GET[‘1’],
‘2’=> $_GET[‘2’]
) ;
$arr = array_map(‘intval’, $NAMES) ;
system($arr[‘1’]) ;
第五行代码调用了array_map函数,并且数组中每个元素都进行了intval从操作,因此需要收集这里的一个净化信息,为后续污点分析提供依据。
(7) 获取文件句柄
一些文件操作类型的危险函数的文件参数是以resource传递进来的,因此如果仅仅去判断是否受污染是不可行的,所以需要对获取文件句柄的函数进行分类。
(8)白名单机制
在条件分支中遇到这些函数如in_array,array_key_exists等函数,可以默认是
一种基于白名单的净化处理。
(9)正则表达式校验
比如preg_match和ereg函数,这里不可能去分析具体的正则表达式,因此
为了减少误报,可以认为调用这些函数进行校验都是有效的过滤。当然如果选择牺牲误报而减少漏报,也可以认为这些函数的调用是不起作用的,可以直接报警。
(10)其他函数
其他不属于上述类别但是需要额外分析的内置函数。
2.1.2.4 数据流分析
数据流分析层所做的工作是收集程序中的变量值传递、特殊函数调用等信息。可以理解为数据流分析就是一个综合的程序信息搜集,目的是为了给后续的污点分析提供详细的参考信息。
对于数据流向的识别和搜集,应该考虑到以下两种情况:
针对代码中的赋值语句
PHP内置函数导致的隐藏数据流,比如调用list、func_get_args等函数。
执行分析的流程图如下:
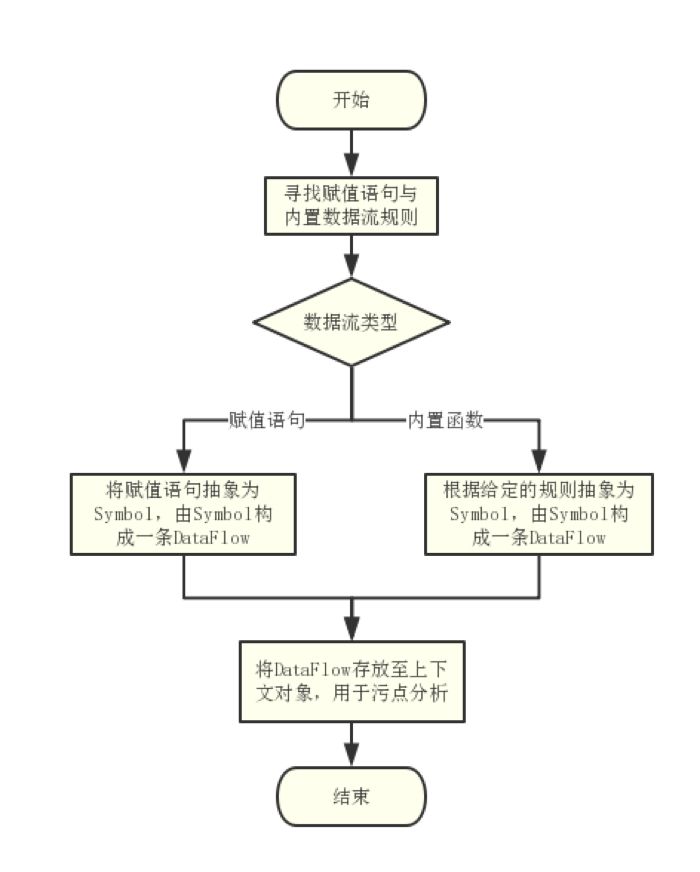
2.1.2.5 污点传播分析
污点分析过程是在程序分析中,一旦发现危险函数的调用则启动分析。对传入危险函数的危险参数进行分析,结合数据流分析时该危险参数的一些程序信息,如净化信息、内置函数处理信息等进行判断,如果一旦发现该变量可以被用户控制并且没有进行有效过滤,则判定为漏洞。
定义危险函数
首先我们来考虑如何定义危险函数。在人工代码审计的时候,我们会按照漏洞的类型着重关注某一批函数,比如mysql_query, file_get_contents, eval等等。然后我们会找到这些函数的某些参数,然后判断这些参数是否经过程序处理后还是会存在漏洞。因此,污点分析时,只需要关注危险函数的名称和危险参数的位置即可,配置示例如下:
print => array(array(1),$F_SECURING_XSS)
该配置的含义是:print函数是一个可能引发XSS漏洞的危险函数,并且其参数1是一个危险参数。
定义净化操作
定义一个参数是否受到了有效净化是污点分析中比较重要的环节,这关系到后续漏洞判定的准确性。根据人工代码审计的经验,我们可以抽象总结出一个PHP实现的净化操作可以有以下方式:
(1)使用PHP内置的或者用户自定义的净化函数执行净化,比如调用addslashes等函数
(2)使用PHP内置的一些校验类型的函数,比如类型判断、正则表达式校验、字符串切割、回调函数以及编码解码等操作。这些操作都会进行一定程度的净化,如果在实践中,我们期望有较高的精确度,则可以认为凡是调用这些函数,就认为是有效的净化;如果我们期望降低漏报率,则可以忽视这些内置函数影响或者执行更加细致的分析。
(3)使用逻辑判断进行校验,如使用了==或者===与某些静态常量进行了比较操作,则认定为该变量接受了净化。
执行污点分析
有了上述基础,我们可以很清晰地执行污点分析判断漏洞了,大致的过程如下:
(1)在执行数据流分析过程中,如果发现了敏感函数的调用,则启动污点分析。
(2)查询危险函数配置列表,获取到需要判断的危险参数列表。
(3)向上找到连接的基本块信息,关注一个基本块内所有的数据流记录,找到数据流记录右边的值,提取出该变量。
(4)如果该变量进入到了内置函数,则按照之前章节中整理的内置函数的作用判断是否受到了有效的净化。
(5)当遍历时找不到基本块中相关的赋值语句,或者赋值的值为字符串、数字或者布尔值,则停止污点分析。
此外,我们需要格外注意编码和解码的影响,:
(1)一个回溯变量被进行解码操作后(base64/hex/zlib…),该变量向上的所有净化操作都可以认为是无效的。
(2)如果一个变量被编码和解码多次,则进行抵消分析操作,并由抵消之后的结果进行判断。
2.1.3 其他分析层
在整个语法树遍历、控制流图生成的过程中,可能还会伴随着以下几种情况的细致分析:
(1)过程内、过程间分析
当我们分析代码时,会遇到方法内部的变量传递与程序信息搜集;或者会遇到一个变量在多个方法之间通过参数进行传递。支持过程内、过程间分析的重点是作用域之间的对应和转换。此外,当我们遇到某个函数中执行了对某个参数的过滤,我们可以将其加入到净化函数列表,比如分析以下代码:
<?php
function escapeCmd($cmd){
returnescapeshellcmd($cmd) ;
}
system("ls -l ".escapeCmd($_GET['cmd'])) ;
?>
这里在执行分析时,遇到escapeCmd这个用户自定义函数的调用,因此需要在上下文中寻找该方法的方法体(定义)并分析该方法的程序段。当发现其调用了安全函数escapeshellcmd后,我们就可以把这个escapeCmd加入到命令注入漏洞的安全函数中。
(2)多文件分析
执行多文件分析时,很多系统仅仅只是依赖use、include、require等关键词来寻找当前文件所包含的其他文件,但是很多程序实现中,往往会用到autoload技术,或者在某个统一入口执行文件包含的操作。所以我们有很大的几率会遇到某个文件中调用了一个其他文件的方法,但是在该文件中却找不到该方法的定义语法结构的情景。
因此多文件分析时,我们最好在分析初始化阶段中获取到所有类定义、方法定义、通用函数定义以及其所在的路径位置,将这些信息保存在内存中。当我们后续分析时,可以直接操作该内存结构,动态提取需要的方法定义。
三、企业级研发与部署方案
3.1 企业级实际场景和挑战
或许很多人会认为,源代码安全扫描只需要把代码拿来扔给扫描器扫描,然后产生打印结果给业务线就行了。可事实上在大型互联网企业中部署并不是那么简单的一件事,主要考虑一下问题:
非本地工具,而是一个平台
在大型公司,可能有成千上万的产品线,涉及到的代码库数量庞大并且编程语言繁杂,面对这种状况,本地化工具过于松散,不好管理,接入效率低的缺点,而统一的扫描平台可以提供一整套的自动化接入方案。统一的源码安全扫描平台可以区分多场景的任务类型,提供多种接入方式,可以更高效、自动化地提供安全扫描能力。
软件开发关键环节,中流砥柱
SDL(securitydevelopment lifecycle) 是微软提出的从安全角度指导软件开发过程的管理模式,源代码安全扫描是SDL方法中的重要环节。从软件的开发流程上看,源代码安全扫描处于软件开发流程上下游,在软件上线之前需要通过安全扫描。
在我们的实践中,源代码安全扫描是以插件的形式,嵌入到软件研发的流程中,为业务线代码保驾护航。

这将要求平台必须具有高可用性,高响应及时度和完善的用户反馈机制。
战略地位,支撑安全红线
企业有一条安全红线,业务必须遵守的最基本安全要求。源代码安全扫描也可以用于在系统上线前发现漏洞与违规的内容,禁止漏洞带到线上,一定程度保护企业业务安全。
3.2 整体架构
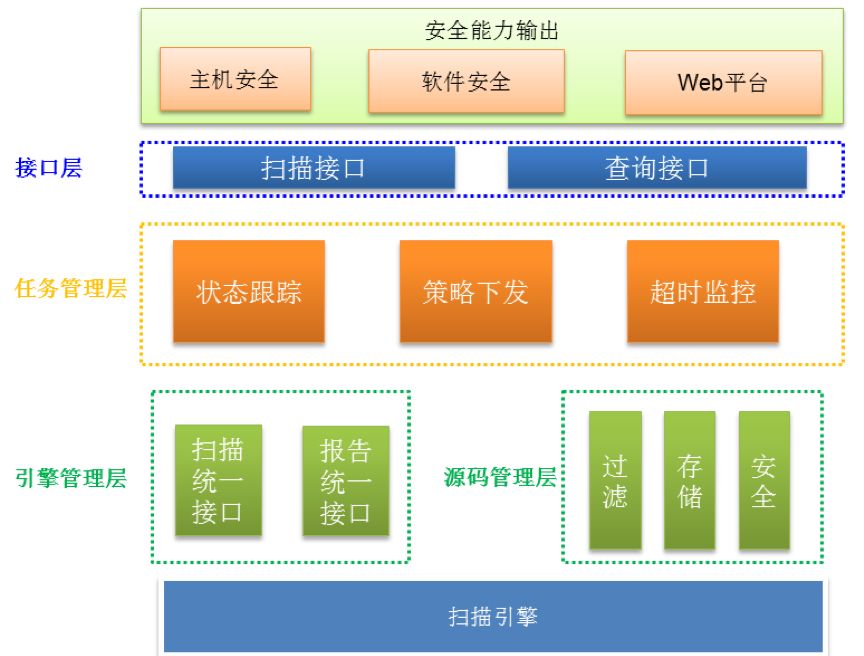
从分层的角度,源码安全扫描平台大致分为五层,每一层都有明确的职责划分。
3.2.1 接口层
接口层是平台对外输出能力的入口,主要对接口请求进行合理性校验,权限校验,参数校验,以确保请求是合法的,非恶意的。功能上主要分扫描接口和查询接口,扫描接口用来接收发起扫描任务,查询接口用来查询扫描任务的结果数据。
3.2.2 任务管理层
每一次扫描就是一个任务,任务管理层是整个平台的中心部分,管理所有任务的扫描状态。主要包括三个职责:
1)状态跟踪。任务管理层跟踪和记录所有任务的扫描状态。
2)策略下发。源码扫描平台根据业务的实际场景,针对不同任务实施不同的扫描策略,比如根据代码的变更情况使用缓存策略,根据代码库的特性调整超时时间等。
3)超时监控。每个任务都有一个超时时间,当任务扫描时间超过期望值,任务会结束并返回超时异常。
3.2.3 引擎管理层
引擎管理层是对引擎调用的一层封装,在企业里面涉及到多种计算机语言,不同语言可能使用不同的源码分析引擎。引擎管理层向上抽象出扫描接口和报告接口,扫描接口接收扫描数据,下层实现具体的引擎调用策略,报告接口获取不同引擎的扫描结果,统一生成扫描分析报告数据。
3.2.4 源代码管理层
源代码管理层主要关注目标源码获取、源码存储和源码安全。
1)源码获取。源码获取主要支持两种方式,第一是用户上传源码的方式,这种方式需要用户自己把源码打包,上传到web服务器。第二种是和企业级代码托管平台打通,源码管理层根据托管平台提供的安全协议拉取源码。
2)源码存储。源码存储主要包括两个方面,其一是需要扫描的源码,这部分源码存储时间不长,在扫描结束后的一段时间内会被清除;其二是有漏洞的源码,这部分源码会被永久存储,用来后续分析漏洞报告使用。
3)源码安全。源码安全扫描涉及到业务线的源码下载与分析,对于企业来说源码具有最高保密性,需要防止源码泄露的问题发生。这里我们有两个层面措施:第一是服务器隔离,所有对源码操作和源码存储都放在指定的服务器上,并且由源码托管平台负责,这种物理隔离大大减少平台自身的管理成本。第二是所有源码存储传输都采用了加密,这里采用常用的方式,使用AES加密源码,RSA加密AES的key。
3.2.5 扫描引擎
引擎主要利用静态代码分析技术分析源码中可能存在的漏洞,具体参考“自动化代码挖掘技术”章节。
3.3 SDL中的实践
研发工程师(RD)提交代码,进行源码安全扫描,编译,持续集成到部署上线,这一系列步骤是全自动化的过程,而源码安全扫描嵌入到整个流程中,必定牵扯到各个平台。这里我们分享这个过程遇到的问题。
3.3.1 接口可用性
一般平台的接口可用性要求是四个9,即SLA为99.99%,即使企业内部使用,也要达到99.9%。SLA指标很重要,因为一旦某段时间内接口不可用导致软件持续集成阻塞,会影响到正常的产品发布的流程,导致产品上线出问题。比如企业内某个产品紧急修复了bug需要上线,但是却在安全扫描这一步卡住,产品线的同学可能会抓狂了。
为了保障我们接口的可用性,以及及时发现故障,我们做了以下策略:
慢启动。接口的服务逻辑应该尽可能少的计算和IO访问,这里我们仅仅将请求的原始数据做一次redis写入,然后就返回,其他的任务扫描逻辑之后才被后续的逻辑“慢”启动起来。
接口监控。我们监控每个接口每次接收请求到做出响应的时间,在响应时间超出一定范围(一般与调用平台约定),则进行邮件告警。
降级策略。在遇到故障无法在短时间内恢复的情况,我们启动降级策略,舍弃一定功能的情况下,保障接口能够及时返回,防止流程卡住。
3.3.2 “慢”是永恒话题
源码安全扫描作为软件集成发布的一个步骤,一定程度上影响软件发布的时间。如果安全扫描耗时过长,将会大大拖累的整个上线流程,安全部本身也会承受着很大的压力。
3.3.2.1 此增量非彼增量
或许有人会讲,RD大多数时候可能只会修改几个代码库的文件,这样怎么会有扫描速度慢的问题呢?这样的想法是基于两个前提:第一,扫描是单文件;第二,文件与文件之间是没有关联的。但事实上,前面漏洞分析技术也有提及,白盒代码扫描过程其实会对相关联的多个文件进行扫描,可能修改了一个文件,但是有很多其他的文件引用了这个文件,为了保险起见,所以会把相关联的文件一并执行扫描。
所以一开始的做法是:不管代码库如何变化,都使用全量扫描,而这将导致扫描速度特别“慢”,经常会收到业务线同学的反馈,对运营造成很大的压力。
3.3.2.2 增量扫描的实践方法
为了提高扫描的性能,我们尝试做了增量扫描策略。
大致思路是,如果我们能够对本次变更的代码进行分析,找出当前代码库中变更文件引用的文件和被引用的文件,将这些文件进行扫描,最后跟全量合并结果。这样可以大大减少扫描的文件数,提高扫描速度。
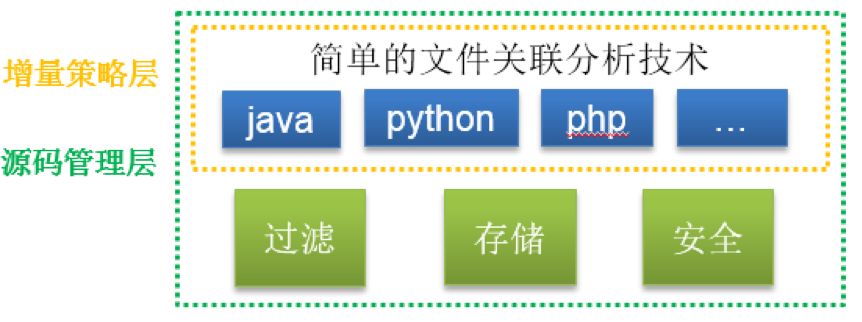
具体做法是,在源码管理层嵌入增量策略层,利用简单的源码分析技术,得出文件的引用流向图。通过对图的遍历获取到增量涉及到的文件。
3.3.2.3 其他优化策略
除了增量扫描,我们还有如下优化策略:
无变更文件使用历史结果。相同代码库前后两次扫描,如果文件没有任何修改,则认为两次扫描结果一致。
基于无关文件变更的缓存策略。一个代码库,前后两次扫描,如果前后两次变更的文件与安全扫描无关,则复用第一次扫描结果。
闲时扫描。很多时候扫描慢也可能是资源紧缺有关,一个平台的访问量也可能集中在某个时间段,因此,闲时扫描作为一种缓存策略,可以大大提高扫描的速度。
四、平台检测效果
4.1 总体检出效果
静态代码安全扫描嵌入开发流程以来,接入代码库数量达到3000+,其中每天由代码托管平台触发的增量任务有1700+个,由上线平台触发的任务有2500+,根据我们的优化方案,95%的任务能够在10分钟内完成。我们的漏洞检测规则加入人工运营和自定义开发,漏洞准确率达到90%左右,其中不同的语言漏洞的分布情况不一样。
目前我们php检测覆盖13中类型漏洞, java语言扫描覆盖30+种类型漏洞,其中除了web常见漏洞外,还覆盖部分android,python,nodejs漏洞。
4.2具体检测场景与能力
4.2.1 PHP漏洞检测
关于PHP的漏洞检测手段详见第二章节。
4.2.2 java漏洞检测
java白盒检测需要覆盖owasp主要web漏洞,同时也需要对一些第三方开源库已知漏洞进行覆盖,因此针对通用漏洞和第三方开源库nday,我们采取了不同的检测方法。
第三方开源库已知漏洞
java通过加载第三方库,由于第三方库可能存在已知高危漏洞,例如struts2存在s2-056,spring-boot存在表达式注入等漏洞。针对这一类由于老版本组件使用导致的漏洞,可以通过版本检查进行覆盖,大多数版本均可在pom.xml或者build.gradle文件中查询到,例如struts2:
<dependency>
<groupId>org.apache.struts</groupId>
<artifactId>struts2-core</artifactId>
<version>2.5.16</version>
</dependency>
此时可以通过检测struts2-core版本是否在漏洞范围以内,即可判断是否存在漏洞。但这种方法无法检测业务线同学通过修改代码或者添加过滤器修补漏洞,而这需要通过数据流分析来解决。
通用漏洞
通用漏洞主要覆盖一些高危或者中危漏洞,例如sql注入、命令执行、代码执行、SSRF、任意文件上传等。对于任意一种漏洞,都需要首先获取漏洞的输入点与触发点以及漏洞的数据流,以简单的sql注入为例:
protected void processRequest(HttpServletRequestrequest, HttpServletResponse response) throws ServletException, IOException {
String user = request.getParameter("user");
Statement st = conn.createStatement();
String query = "SELECT * FROM User where userid='" + user +"'";
ResultSet res = st.executeQuery(query);
}
首先需要获取到输入方法HttpServletRequest::getParameter(),触发点executeQuery(),然后通过数据流进行分析,这里的数据流可以确定为:
通过跟踪数据流即可确定是否存在漏洞,当然这属于最简单模式,实际检测漏洞中为了减少误报,我们还需要处理以下几种情况:
包含对某些漏洞的全部过滤机制,例如针对sql注入的全局filter
数据流中是否包含if、过滤函数等过滤节点
某些数据流是否已经中断,例如文件上传中,文件后缀在数据流图中已经被更改,实际上已不可控,此时需要单独处理类似数据流
框架的处理
java由于拥有众多开源框架,而大多数开源框架均有一定的安全机制,因此某些漏洞在特定的框架中可能并不符合通用模式。以mybatis注入为例:
<select id="orderBlog" resultType="Blog"parameterType=”map”>
SELECTid,title,author,content
FROM blog
ORDER BY ${orderParam}(#{orderParam})
</select>
对于mybatis来说,如果sql语句变量的引入采用#{}的方式,则sql语句底层直接采用的预编译的形式,此时不需要再检测sql注入漏洞;而如果采用${}形式,则需要按照一般的sql注入流程检测。因此java的大多数通用漏洞检测,还需要对使用量较大的框架进行适配,此时在输入和触发点的获取上适配即可。上面的例子,就可以在检测输出时,首先判断是否为mybatis应用,如果未mybatis应用,则直接检测是否在sql语句中引入了${}类型变量,然后就可以按照通用方式检测了。
4.2.3 Python/Nodejs漏洞检测
python和nodejs的漏洞主要是命令执行、代码执行、sql注入、XSS与SSRF,两者的检测思路大致相同。首先根据不同的框架确定输入,python的主要web框架有python-cgi(原生)、Django、Flask、webpy,而nodejs主要有express、trails等。
例如:
class index:
def GET(self):
data = web.input()
在检测python时,首先需要通过正则判断是否为web应用,然后根据不同框架获取不同输入函数即可。而python的主要有:eval、exec、execfile、pickle.*、cPicke.*、timeit.timeit等。
简单的python漏洞示例:
classindex:
def GET(self):
data= web.input()
code= data.get('code','')
return eval(code)
这个代码片段中,web.input()->data->code->eval能够形成完成的漏洞数据流,同时包含了可控制输入与漏洞触发点,因此就可以确认为一个漏洞。而为了准确的检测漏洞,某些安全使用方式需要过滤,例如
eval(code,{"__builtins__":None},safe_dict)
这里通过将__builtins__置为空,以及设置安全白名单函数,可以较好防御代码执行,因此对于这一类需要通过eval的参数数量进行判断。
五、总结
基于语义分析、语法分析技术,并且将各个语言和框架特性进行集成和识别而构建的静态代码安全扫描器,无论是误报率还是检出率都远远低于传统的商用扫描器。
此外,将自动化的静态代码安全扫描嵌入到开放与上线流程中,可以有效地在上线前阶段就发现代码中的安全漏洞,并将源代码漏洞报告第一时间推送给业务线的开发同学进行修复,做到防患于未然。
而安全部门需要做的就是持续运营安全扫描规则,处理误报反馈与安全能力增强上,可以在人工代码审计上节省很多人力。
对于大型互联网公司,拥有可以与CI流程进行结合的源码安全扫描平台是非常必要的,源码安全扫描不仅可以对安全漏洞进行扫描,还可以配合一些源码指纹识别技术与安全开发规范,对内部的一些高危开源框架、不良的编码习惯进行有效治理,可谓一举多得。
本文来自百度安全EnsecTeam,作者隐形人真忙、sharker、arnoxia 转载需注明出处及本文链接