
热门主题




学点算法搞安全之HMM(上篇)
2017-12-01 14:44:5510795人阅读
前言
隐式马尔可夫(HMM),也称韩梅梅,广泛应用于语音识别、文本处理以及网络安全等领域,2009年I Corona,D Ariu,G Giacinto三位大神关于HMM应用于web安全领域的研究论文,让HMM逐渐被各大安全厂商重视。本篇重点介绍HMM最常见同时也比较基础的基于url参数异常检测的应用,后继文章将介绍HMM结合NLP技术在XSS、SQL、RCE方面的应用。"多一个公式少一半读者",所以霍金的《时间简史》和《明朝那些事》一样畅销,我的机器学习系列文章都是尽量少讲概念,多讲例子,希望可以让机器学习被更多人了解和使用。
HMM基础原理

现实世界中有一类问题具有明显的时序性,比如路口红绿灯、连续几天的天气变化,我们说话的上下文,HMM的基础假设就是,一个连续的时间序列事件,它的状态受且仅受它前面的N个事件决定,对应的时间序列可以成为N阶马尔可夫链。
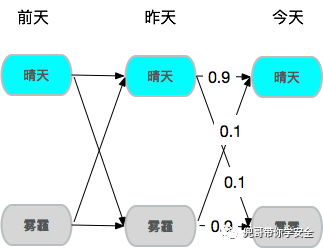
假设今天是否有雾霾只由前天和昨天决定,于是就构成了一个2阶马尔可夫链,若昨天和前天都是晴天,那么今天是晴天概率就是90%。
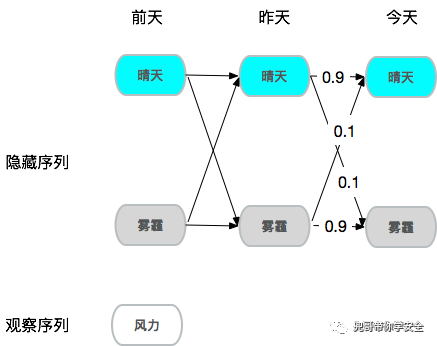
稍微再复杂点,假设你想知道2000公里外一个城市的雾霾情况,但是你没法直接去当地看到空气情况,手头只有当地风力情况,也就是说空气状态是隐藏的,风力情况是可观察的,需要观察序列推测隐藏序列,由于风力确实对雾霾情况有较大影响,甚至可以假设风力大的情况下90%概率是晴天,所以通过样本学习,确实可以达到从观察序列推测隐藏序列的效果,这就是隐式马尔可夫。
URL参数建模
常见的基于GET请求的XSS、SQL注入、RCE,攻击载荷主要集中在请求参数中,以XSS为例:
/0_1/include/dialog/select_media.php?userid=%3Cscript%3Ealert(1)%3C/script%3E
正常的http请求中参数的取值范围都是确定的,这里说的确定是指可以用字母数字特殊字符来表示,并非说都可以用1-200这种数值范围来确定。以下面的几条日志为例:
/0_1/include/dialog/select_media.php?userid=admin123
/0_1/include/dialog/select_media.php?userid=root
/0_1/include/dialog/select_media.php?userid=maidou0806
/0_1/include/dialog/select_media.php?userid=52maidou
/0_1/include/dialog/select_media.php?userid=wjq_2014
/0_1/include/dialog/select_media.php?userid=mzc-cxy
肉眼观察可以归纳出userid字段的由字母数字和特殊字符'-_'组成,如果你足够强大可以看完上万的正常样本,甚至都可以总结取值范围为[0-9a-zA-Z-_]{4,}。如果有上亿的日志上百万的参数,人工如何完成?这时候机器学习可以发挥作用了。
以uid字段为例,uid的取值作为观察序列,简化期间可以对uid的取值进行泛化,整个模型为3阶HMM,隐藏序列的状态只有三个S1、S2、S3:
[a-zA-Z]泛化为A
[0-9]泛化为N
[\-_]泛化为C
其他字符泛化为T
比如:
admin123泛化为AAAAANNN
root泛化为AAAA
wjq_2014泛化为AAAACNNN
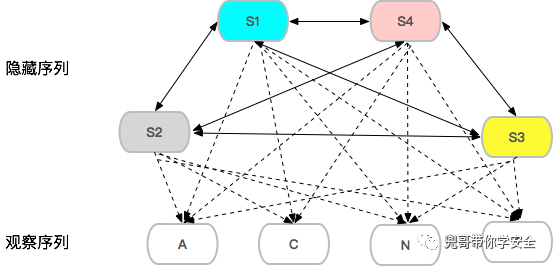
隐藏序列就是S1-S4三个状态间循环转化,这个概率称为转移概率矩阵,同时四个状态都以确定的概率,以观察序列中的A、C、N、T四个状态展现,这个转换的概率称为发射概率矩阵。HMM建模过程就是通过学习样本,生成这两个矩阵的过程。生产环境中泛化需谨慎,至少域名、中文等特殊字符需要再单独泛化。
数据处理与特征提取
由于每个域名的每个url的每个参数的范围都可能不一样,有的userid可能是[0-9]{4,},有的可能是[0-9a-zA-Z-_]{3,},所以需要按照不同域名的不同url不同参数分别学习。泛化过程如下:
def etl(str):
vers=[]
for i, c in enumerate(str):
c=c.lower()
if ord(c) >= ord('a') and ord(c) <= ord('z'):
vers.append([ord('A')])
elif ord(c) >= ord('0') and ord(c) <= ord('9'):
vers.append([ord('N')])
else:
vers.append([ord('C')])
return np.array(vers)
友情提示,为了避免中文等字符的干扰,ASCII大于127或者小于32的可以不处理直接跳过。
从weblog中提取url参数,需要解决url编码、参数抽取等恶心问题,还好python有现成的接口:
with open(filename) as f:
for line in f:
#切割参数
result = urlparse.urlparse(line)
# url解码
query=urllib.unquote(result.query)
params = urlparse.parse_qsl(query, True)
for k, v in params:
#k为参数名,v为参数值
友情提示,urlparse.parse_qsl解析url请求切割参数时,遇到';'会截断,导致获取的参数值缺失';'后面的内容,这是个大坑,生产环境中一定要注意这个问题。
训练模型
安装hmmlearn
hmmlearn是python下的一个HMM实现,是从scikit-learn独立出来的一个项目,依赖环境如下:
Python >= 2.6
NumPy (tested to work with >=1.9.3)
SciPy (tested to work with >=0.16.0)
scikit-learn >= 0.16
安装命令如下:
pip install -U --user hmmlearn
训练模型
将泛化后的向量X以及对应的长度矩阵X_lens输入即可,需要X_lens的原因是参数样本的长度可能不一致,所以需要单独输入。
remodel = hmm.GaussianHMM(n_components=3, covariance_type="full", n_iter=100)
remodel.fit(X,X_lens)
训练样本得分为:
score:16 query param:admin123
score:9 query param:root
score:21 query param:maidou0806
score:16 query param:52maidou
score:15 query param:wjq_2014
score:12 query param:mzc-cxy
模型验证
HMM模型完成训练后通常可以解决三大类问题,一类就是输入观察序列获取概率最大的隐藏序列,最典型的应用就是语音解码以及词性标注;一类是输入部分观察序列预测概率最大的下一个值,比如搜索词猜想补齐等;另外一类就是输入观察序列获取概率,从而判断观察序列的合法性。参数异常检测就输入第三种。
我们定义T为阈值,概率小于T的参数识别为异常,通常会把T定义比训练集最小值略大,在此例中可以取10。
with open(filename) as f:
for line in f:
# 切割参数
result = urlparse.urlparse(line)
# url解码
query = urllib.unquote(result.query)
params = urlparse.parse_qsl(query, True)
for k, v in params:
if ischeck(v) and len(v) >=N :
vers = etl(v)
pro = remodel.score(vers)
if pro <= T:
print "PRO:%d V:%s LINE:%s " % (pro,v,line)
以userid=%3Cscript%3Ealert(1)%3C/script%3E为例子,经过解码后为<script>alert(1)</script>,范化后为TAAAAAATAAAAATNTTTAAAAAAT,score为-13945,识别为异常。
总结
本文介绍了HMM在web安全的基础应用,由于仅依赖参数的文本特征进行异常检测,虽然理论上只要白样本足够多确实可以识别几乎所有基于GET请求参数的未知攻击,但是由于缺乏语义层面异常检测,误报率比较高。另外扫描器等对结果的影响很大,如何进一步提升检测能力,请看下篇。
本文来自兜哥带你学安全,原文链接:兜哥带你学安全
文章图片来源于网络,如有侵权请联系我们