恶意软件检测就是一场攻防(猫鼠)游戏,防守者每提出一种检测技术,攻击者就会开发出新的避免检测技术。比如,基于签名的检测提出后,攻击者就使用封装、压缩、变型、混淆等方法来避免被检测到。还有API hooking和代码注入方法也被用于避免基于行为的检测。随着机器学习技术的发展,机器学习也成为网络攻防追逐的方向。
其中一种增强机器学习系统鲁棒性来避免被绕过的技术是生成对抗样本(generating adversarial samples),是一种经过修改的输入数据来让机器学习系统产生错误的分类。对抗样本不仅可以让机器学习系统进行恶意操作,还可以用来改善机器学习系统的效率。
对抗样本使机器学习系统更鲁棒
对抗样本可以找出机器学习模型的弱点,然后改进这些弱点就可以增强模型的鲁棒性。用大量从恶意软件样本修改后的样本可以不断的探测机器学习系统的能力。这样,对抗样本就可以重训练机器学习系统来让系统更加鲁棒。
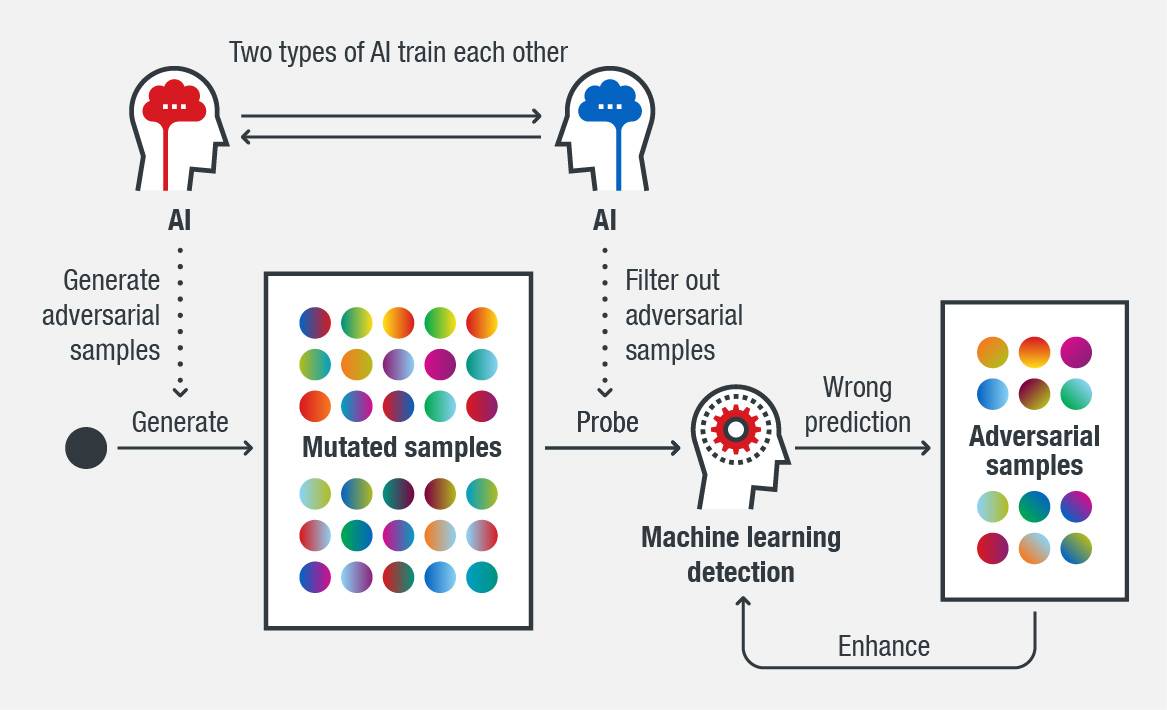
图1. 用对抗样本和AI使机器学习系统更加鲁棒
在系统中,如果文件被系统检测给出的分值较高,就是说与机器学习训练集中的对抗样本相似度高。研究的目标就是通过修改恶意软件样本以减少这种高概率值,直至检测不到。如果成功了,那么就说明找到了机器学习的弱点,这样可以通过一系列动作来解决这些弱点,比如识别新的特征、研究相关的恶意软件、使用其他组件来识别变种等等。
研究人员用一个恶意软件样本作为种子(m),一个表示可能的变化的值(10,20等等)。在研究中,m是32,意味着预定义了32种可能的方式来修改恶意软件文件。通过遗传算法(genetic algorithm,GA),研究人员将产生的变化结合在一起,然后应用到恶意软件中来避免被检测到。下面是具体的步骤:
1.基于种子文件,生成一批新文件(m种变化中的n种变化);
2.得到这些文件机器学习模型预测的结果(是否检测为恶意软件)和梯度信息(概率值);
3.如果循环N次,收集所有未检测的文件,然后退出;
4.选择X个文件作为新种子,种子文件应该包含检测到的和未被检测到的文件,但应保持最小的概率值;
5.将种子文件中的变化和新的随机变化随机融合,生成新的文件;
6.重复步骤2。这些变化可能会破坏或使用PE文件不能运行,使用沙箱技术验证新生成的文件是否可以执行。
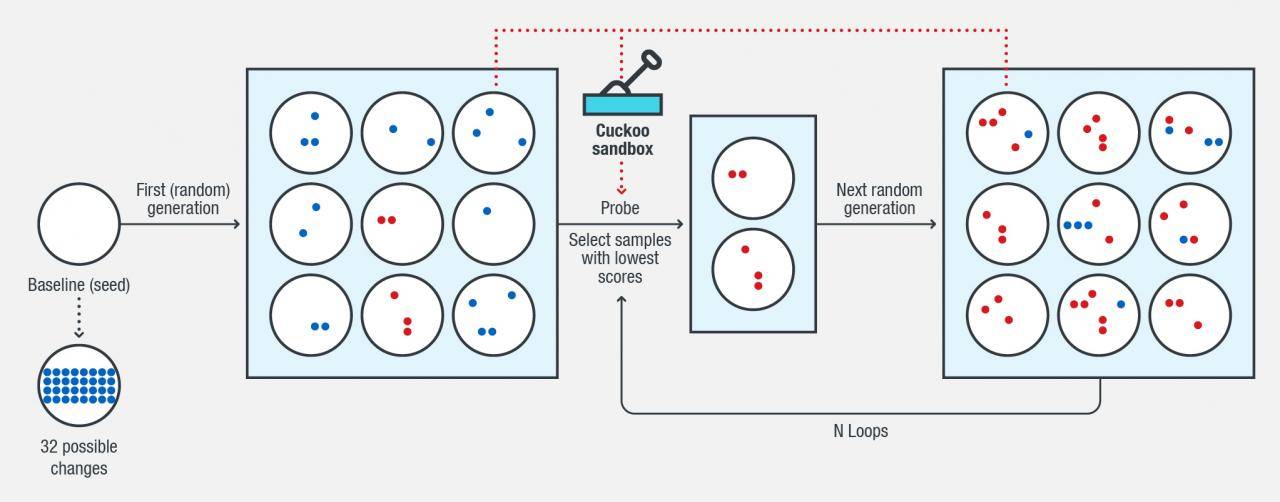
图2. 如何用遗传算法生成对抗样本
研究人员同时发现输出的概率值可能是一个安全漏洞,因为攻击者可以利用它来探测机器学习系统的功能。因此,该数应该隐藏在安全产品中。没有概率输出的指导,就很难用暴力破解的方法去生成对抗样本了。研究人员发现,隐藏了概率值后,暴力破解方法仍然可以生成样本,只不过生成速度变慢了。
在生成对抗样本时,需要考虑两个主要因素:
一是如何在不破坏PE文件的前提下安全的修改PE文件;
二是如何高效的生成不被检测到的样本。
对第二点,AI可以用来选择正确的文件特征,并对这些特征进行改变。但是在测试过程中会花费大量的时间来各种变化的结合来生成有效的对抗样本。机器学习可以帮助选择最有用的变化或结合方式,这可以减少梯度信息,让对抗样本生成的效率更高。
保护机器学习系统避免潜在的入侵方法和其他攻击
在使用对抗样本增强机器学习系统鲁棒性时,有一些安全漏洞也可能会暴露给攻击者。比如,研究人员给恶意软件样本中添加一些正常的字符使其看起来更加真实,并不会被系统检测到;攻击者也可以用感染真实PE文件、编译含有恶意代码的真实源码、注入二进制代码的方式来绕过检测。因为这样恶意文件的结构就和原始真实文件一样了,所以机器学习系统会认为这不是恶意软件。这也会给机器学习系统带来挑战,如果不仔细考虑这种情形的话,一些机器学习系统可能就不能检测出恶意软件的变种样本。
机器学习训练集投毒是另一个需要关注的问题。因为机器学习系统训练集中包含与真实文件相似的恶意软件样本,这可能是假阳性的。比如PTCH_NOPLE恶意软件修改了Windows操作系统的DNS客户端应用程序接口API文件dnsapi.dll,一些机器学习系统的检测结果假阳性就很高。
为了应对针对安全领域机器学习绕过的方法和其他类型的攻击,研究人员提出一些缓解的技术:
1. 通过减小机器学习系统的攻击木来建立基础设施级的防护,其中包括:
· 不将系统暴露给探针或尽量少的让系统暴露给探测系统。攻击者可以使用有本地机器学习模型的免费工具来提供过修改样本来探测机器学习系统。基于云的系统可以防止此类事件的发生,所有机器学习系统的预测都可以记录到后台。什么人、什么时候尝试探测系统都会进行记录。对此类工具的传播和使用应该进行限制。
· 使用多种检测技术结合的安全产品。有了安全产品,攻击者就不会知道到底机器学习模型检测到了哪个样本。
· 隐藏机器学习系统的真实梯度信息(概率值)。
2. 要让机器学习系统变得更加鲁棒:
· 首先,要识别处设计阶段的潜在漏洞,对每个参数都要了解。
· 第二,生成对抗样本,并用对抗样本来训练机器学习模型。这可以通过使用遗传算法的黑盒测试、暴力破解计算、白盒测试等方法来实现。
3. 使用生成对抗网络(generative adversarial network,GAN)。GAN有两种类型的AI,一种生成新的数据实例,一种评估这些数据实例的真实性。两类AI可以互相训练和进化。使用GAN是一种更好的自动化生成对抗样本的方法。
4. 为了减少假阳性的检测结果,可以使用既有机器学习模型又有白名单的安全检测方案。
增强机器学习系统安全性
有效的机器学习系统应该能检测已有的恶意软件,还应该能检测对抗样本。使用GAN、GA、暴力破解方法和其他的策略可以使机器学习系统完成这样的任务。这种能力可以让机器学习系统检测更大范围的威胁,并减少假阳性率。
机器学习绕过方法的对策是未来机器学习在网络安全领域应用的关键之一。增强的机器学习系统可以改善检测和拦截的速率。因为攻击者已知在寻找攻防者之间的安全差距,因此多层防御仍然是预防攻击最有效的方法,包括对机器学习、web/URL过滤、行为分析、沙箱、数据中心保护、云环境、网络、和终端的防护。
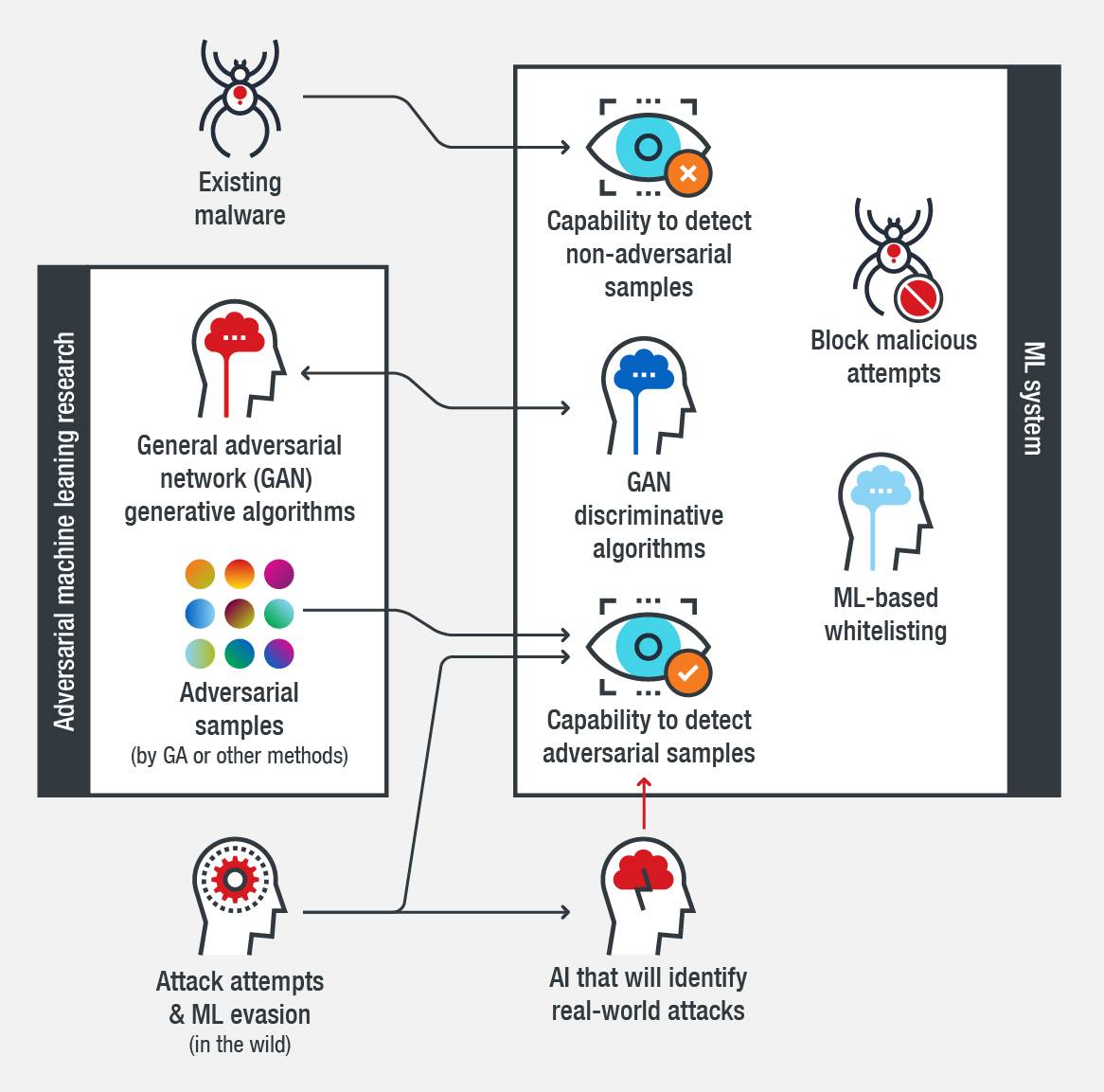
图3. 能够检测和拦截威胁和对抗样本的高效的机器学习系统框图
本文翻译自:https://blog.trendmicro.com/trendlabs-security-intelligence/adversarial-sample-generation-making-machine-learning-systems-robust-for-security/
原文地址: http://www.4hou.com/technology/12896.html
翻译作者:ang010ela 文章图片来源于网络,如有问题请联系我们





